Data AI-Ready的关键因素
上一篇我们翻译了哈佛商业评论的一篇重要文章《您公司的数据是否已准备好用于生成式人工智能》。
事实上大模型技术并没有解决数据孤岛问题。所有企业都要考虑如何让您的数据准备好,基于提示工程结合企业私有知识进行AI应用的落地。
数据AI-ready有以下几个关键因素:
1、元数据管理元数据管理是确保AI-Ready的核心。
元数据提供数据上下文,帮助您理解其含义以及如何使用它。支持从数据发现、质量、血缘的一切。
• 360°查看每个数据资产,获取所有该数据相关上下文
• 端到端主动的数据血缘,以了解数据如何在系统中流动
• 语义层,有助于创建和探索定义、指标和资产之间的关系
• 个性化的访问控制——根据角色、业务领域或项目上下文定义
这些元素将帮助AIGC有效地理解数据资产,并提供有用的建议。
没有出色的元数据管理,LLM不可能有效。

2、元数据质量管理
如前所述,人工智能辅助系统需要高质量的数据才能发挥作用。因此,必须根据最重要的数据质量指标(如相关性、可靠性、准确性等)对您的数据资产进行持续评估。这里经常被忽视的一个方面是元数据质量。在即将到来的人工智能和LLM时代,元数据质量将与数据质量同样重要。
LLM应用程序需要丰富、高质量的元数据才能使用数据。元数据越准确、越可信,人工智能生成的答案就越可靠。

3、数据血缘管理
数据架构与业务架构的关联关系及数据流的血缘关系。数据血缘对于实现Data AI Ready(即数据准备好支持人工智能应用)具有重要的价值。Data AI Ready强调数据的可访问性、可理解性、高质量和高效管理,以便为人工智能(AI)应用提供坚实的基础。以下是数据血缘在Data AI Ready方面的几个关键价值点:
提高数据透明度与可理解性
加强数据质量控制
促进数据合规性
优化数据架构与治理
- 提升AI模型的可靠性与可解释性
这些价值共同构成了数据血缘在支持人工智能应用中的关键作用。
4、数据治理体系
《纽约时报》的Steve Lohr:“数据是大企业构建人工智能的瓶颈。没有标准、上下文和认责的数据是从人工智能系统中创造价值的主要障碍。”没有数据认责和管控系统,您的模型将不断产生幻觉,经常崩溃,并且始终无法实现公司期望的业务价值。
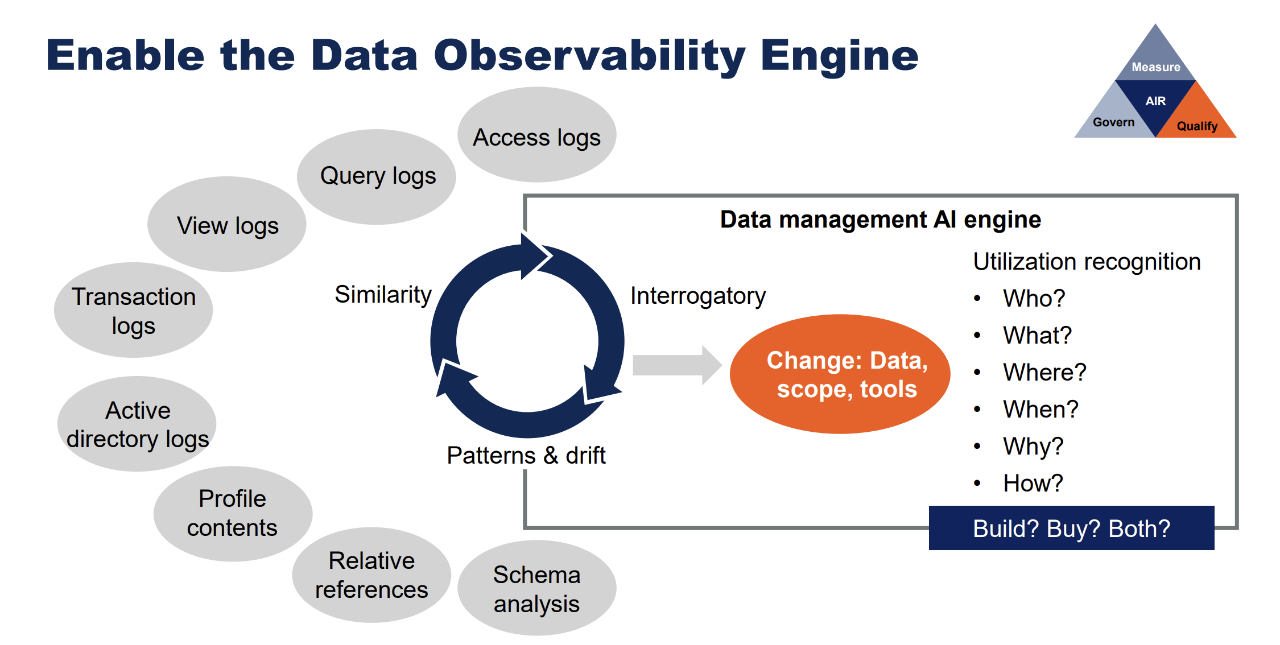
5、数据结构的稳定性
AI算法会根据它们在训练数据中识别到的schema来理解。一致的元数据可确保AI系统在训练后可以继续将其学习到的模式应用于新数据,而不会出现错误或需要重新配置。
数据格式的变化(例如更改列名、更改数据类型或重新组织数据库架构)可能会使AI模型混乱。这可能会导致输出不正确,或者需要额外的时间和资源来使用新结构重新训练模型。
为了保持有效AI分析具有稳定的数据结构,规划时要考虑设计数据架构并对数据架构进行管控。数据模型版本控制,数据模型的完整性和可追溯性。
建立变更管理策略:创建用于评估和实施数据结构变更的管控制度。包括影响评估、变更管理与现有AI系统的兼容性。
6、数据来源的多样性和准确性
人工智能算法受益于广泛的数据输入,因为多样化的数据源有助于减少偏见并提高洞察的准确性。数据来源多种多样,包括不同的供应商、客户统计数据、销售渠道、电子商务网站和第三方市场。这种多样性至关重要,主要原因如下:
减少偏见:人工智能系统可能会根据所训练的数据产生偏见。通过整合来自各种来源的数据,您可以降低这些偏见的风险,因为人工智能解决方案将具有更平衡的视角,可以反映不同的观点。
增强稳健性:多样化的数据源使得人工智能模型对任何单一来源的不稳定信息不敏感。
提高预测能力:利用来自综合输入数据,人工智能算法可以更好地预测不同客户群体和市场条件下的行为和结果。
这里需要注意的是,数据准确性与数据多样性同样重要。在集成新数据源之前,请验证其可信度和记录,并确保您的供应商和数据提供商遵守行业标准和数据管理的最佳实践。
7、人工智能理解的数据结构
AI算法需要易于处理的数据格式。这通常意味着结构化数据,即任何遵循严格格式的数据,便于访问、搜索和分析,通常包括:
定义的数据模型:明确定义schema下的结构化数据- 例如具有行和列的表格 - 其中每个数据元素都有明确的划分。
统一的数据条目:每个条目都遵循相同的格式。例如,在CSV文件中,每一行代表一条记录,每一列代表该记录的特定属性。
8. 数据字段丰富(元数据充足率)
数据字段的内容(元数据)对AI分析的有效性起着重要作用。当数据字段具备全面、详细的信息时,AI系统可以进行更深入、更细致的分析,并提供更个性化的建议。数据字段不止包含名称或价格等基本标识符,也包括详细的产品描述、定义和分类。