


开启数据可视化新旅程:数据血缘的生机与魅力
引言
在当今数字化时代,企业面临着海量且复杂的数据环境。数据如同企业的生命之血,贯穿于各个业务环节,流淌于各种业务系统之间。然而,如何通过上帝之眼对这些不可见无法琢磨的数据一窥究竟、预测它们的未来走向呢?那么数据血缘就是今天我想要和大家分享的主题,我想通过下面5个问题来展开我个人对数据血缘的理解。
一、数据血缘的当前应用困境是什么
数据血缘发展到今天,从来都没有如此的耀眼、如此受关注。本人在近20年前接触过Data Lineage这个名词,是伴随着ETL工具时被提及,是用来解释数据处理逻辑与过程的,更多是数据工程师的袖珍“小册”。
当下,数据血缘不再陌生,而是被业务寄托了更多厚望,“数据链路”这个词也成了很多企业年度信息化规划关键字。一如IT行业其它众多名词,在追捧的过程中难免会存在以下落地应用的困境。
复杂系统和架构: 在当今的企业当中,技术架构的繁杂性已然成为数据血缘需要应对的关键挑战之一。企业的应用平台自早期的Mainframe封闭系统起始,历经 IOE潮流阶段、大数据时期,直至当下的信创特殊阶段,在此过程中,经历了多代技术栈的更迭与交替。如此这般的一系列变化,让数据血缘的梳理和追踪变得困难重重。
例如,当多个业务系统之间的数据交互关系混乱时,我们往往难以准确地追踪数据的来源和流向。这种情况在处理一些核心业务系统(如ERP)时尤为明显,因为这些系统的架构通常都非常复杂且封闭,API接口繁杂、陈旧,要想解析这固若金汤的系统血缘如同痴人说梦。
数据频繁变更与多样的数据流转形式:业务的动态发展会致使数据结构的变更操作频繁出现,进而让数据血缘需要持续地进行更新与维护,这无疑加大了管理的难度。举例而言,在业务流程做出调整之后,相关数据的流转路径就会发生变化。由此,这就需要数据血缘工具拥有实时采集更新以及自动解析维护的功能,从而适应数据环境的迅速变化。
数据流转过程是建立数据血缘的根本,业务为使数据敏捷、畅通采用的技术手段也丰富多样,像SFTP、ESB、ETL工具、流式数据处理、JAVA/Python/Shell 等开发程序、数据库SQL脚本、手工搬运等形式,数不胜数。恰恰是这些复杂的形式,导致了血缘的断裂、缺失以及不可见。
跨部门协作障碍:由于各部门对数据的解读和处理方法各异,这可能会在数据溯源的构建和实施过程中引发沟通和协调上的障碍,使得达成共识变得困难。
举例来说,技术部门和业务部门对于数据血缘的界定和重要性的理解存在分歧。技术部门为了做血缘,恨不得将每个系统、每个字段都梳理出来建立血缘,唯恐有丝毫遗漏,就如一些数据治理项目,需要系统落标率达100%,这种“洁癖”是开展血缘工作时的大忌。又如,业务提出的需求与目标更多是意识形态范畴,过于宏大,太过于高瞻远筑,难以切实落地。因而,创建一个跨部门的合作机制,围绕具体的数据血缘业务场景,使业务目标与项目执行有机结合、对齐。
元数据质量问题:不准确、不完整的数据本身会影响数据血缘的可靠性,可能导致错误的追踪和分析。错误的数据可能误导对数据来源和处理过程的判断。例如,数据库中充斥着大量临时表,这样会直接干扰血缘解析的准确性;又如,每个数据工程师都有自己的程序编写偏好,数据处理的SQL脚本编写不规范,SELECT *的写法在程序中比比皆是;这些都是直接影响血缘解析的重要因素。因此,提高元数据的质量,是提高数据血缘准确性的关键。
数据隐私和安全考虑:在追踪和记录数据血缘时,可能涉及到数据隐私和安全问题,需要在合规的前提下进行操作,增加了复杂性。因此,如何在保证数据隐私和安全的同时,有效地追踪和记录数据血缘,是数据血缘应用的另一个重要问题。
二、如何建立企业精准的血缘地图
随着企业对数据链路应用需求日益渐多,对数据血缘的诉求也愈具个性化,固有数据治理平台中的血缘功能再难以担当起此重任。以数据血缘技术作为基础,将数据治理前、中、后时期的事务操作建立业务场景,将数据开发前、中、后阶段输入建立业务场景,通过血缘技术去预测、校正、监测业务场景的活动,这种多场景应用的数据血缘平台呼之欲出。北京数语科技有限公司正是基于多年数据治理实践经验,将数据血缘模块独立出来,重新设计并推出了多业务场景应用的数据链路监测平台。
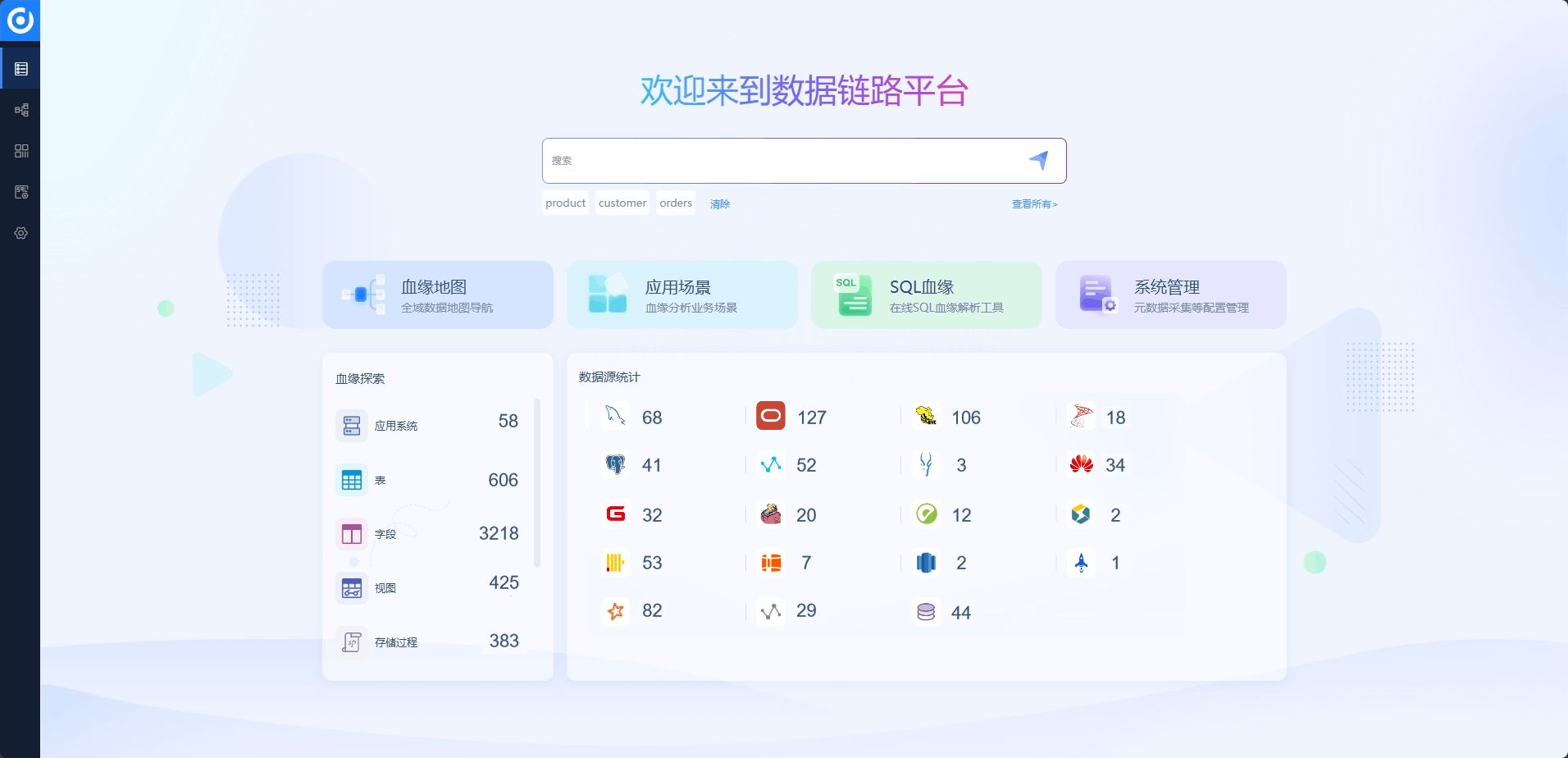
那么,如何利用数据链路监测平台建立起企业精确的血缘地图呢?

在构建企业的数据血缘地图时,首先要进行应用场景设计。这包括设定明确的业务目标,对关联系统进行全面梳理,制定详细的行动计划,并清晰地明确利益相关者。通过明确业务目标,能够为后续的工作指明方向,例如为财务管理提升数据质量、监管指标全链路分析、数据模型变更影响预测。对源头相关系统的梳理有助于了解数据的产生和流转起点。而精心制定的行动计划则能规划出实现目标的具体步骤和时间节点。同时,明确利益相关者能够确保各方在项目中的职责和参与程度。

其次是进行血缘系统建设。这涵盖了对数据血缘工具的评估与选择,进行系统的规划与建设,以及建立相应的管理流程与制度。在评估和选择工具时,要考虑工具的元数据采集是否能覆盖需求、数据血缘解析是否精确、是否具备灵活创建应用场景的能力。系统规划与建设需要根据企业的规模、数据量和业务需求来确定架构和技术方案。管理流程与制度的建设则能确保系统的有效运行和维护。

接下来是血缘采集与认证环节。这要求采集相关系统的元数据,制定合理的任务采集机制,让数据管家和业务方参与到元数据丰富活动中,并对血缘进行认证。采集全面准确的元数据是基础,合理的采集机制能够确保高效和及时。数据管家和业务方的参与能从不同角度丰富元数据,提升其质量。而认证血缘则能保证其准确性、可靠性、连续性。

最后是血缘应用与业务趋动。要将数据血缘链路公开,以驱动业务增效和创新,评估血缘实践的结果,并提出优化细则。公开血缘链路能让更多人了解数据的来龙去脉,从而更好地利用数据。通过评估实践结果,可以发现问题和不足,进而提出优化措施,不断提升数据血缘的价值。
三、怎样打开数据血缘探索之门
数据血缘,原本就在那里。我们怎样以正确方式开启数据血缘探索之门呢?这里我向大家推荐以下2种探索形式。
血缘目录
当明确要探索其中某个数据表单、业务指标的数据血缘关系时,血缘目录则是这种更为精确的搜索工具,就像我们在谷歌搜索结果中筛选新闻、图片、视频等内容一样缩小搜索范围。这种精确的搜索和筛选方式,可以帮助我们更快地找到所需的数据,提高工作效率。
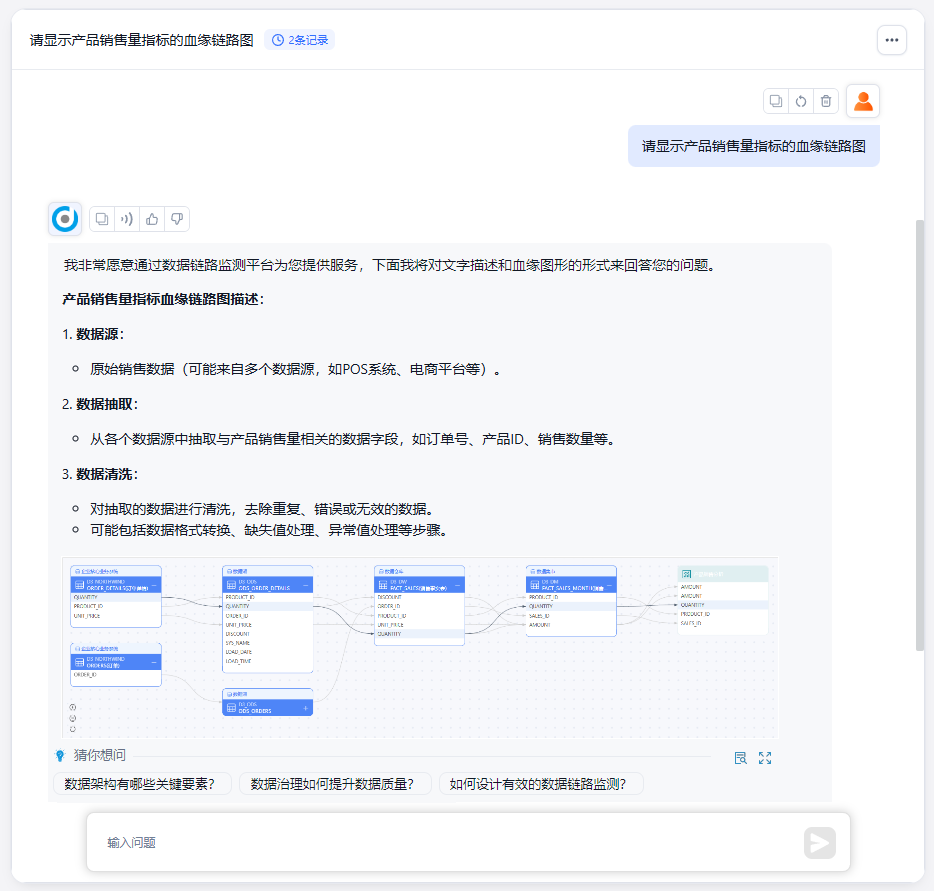
随着AI技术的发展,人们越来越习惯希望通过自然语言对话来寻求所关注的直接答案,基于血缘目录提出具体血缘问题,让它帮助我们快捷找到关注业务指标所对应的数据血缘关系结果,并以缩略图形式呈现出来确认是否进入探索分析模式。
数据地图
数据地图就像我们现实世界的地图,它可以帮助我们从宏观的角度理解数据的全貌。就像我们可以在世界地图上看到各个国家和城市的位置,数据地图可以让我们看到数据的来源、流向和变化。当我们需要深入了解某个特定的数据血缘,数据地图也可以帮助我们“放大”观察,就像我们可以在谷歌地球上放大到埃及金字塔一样。这种由大及小的探索方式,可以帮助我们更好地理解数据的关系和价值。
比如对跨系统间数据流动的路径、形式、时长探索,在地图中去观测哪些数据文件是通过SFTP来流动、哪些数据集是通过ETL工具来调度、哪些数据是通过API来传输、它们所耗时长各是多少?有无变换数据流动形式的可能?如果要建设跨系统间的数据桥梁,哪种技术手段、路径更科学、更经济?这些犹如现实的地图导航,通过直观的血缘地图探索为业务决策和分析提供了更好价值。
总的来说,血缘目录和数据地图是打开数据血缘探索之门的两种重要方式。
四、如何让您的业务融入血缘之路
数据血缘是通过将每个字段、每个代码片、每个数据处理逻辑采集并解释生成的关系链路,每个元素都有自己的“经度”和“纬度”。就如同在浩瀚宇宙中,每一颗星辰都有其独特的坐标。如果要辨认、理解它,就离不开围绕这些元素去叠加业务氛围信息,只有注入了其元素的数据标准、业务流程、业务规则、利益相关者、指标含义等氛围信息后,人们才能通过这些上下文去理解其业务含义。
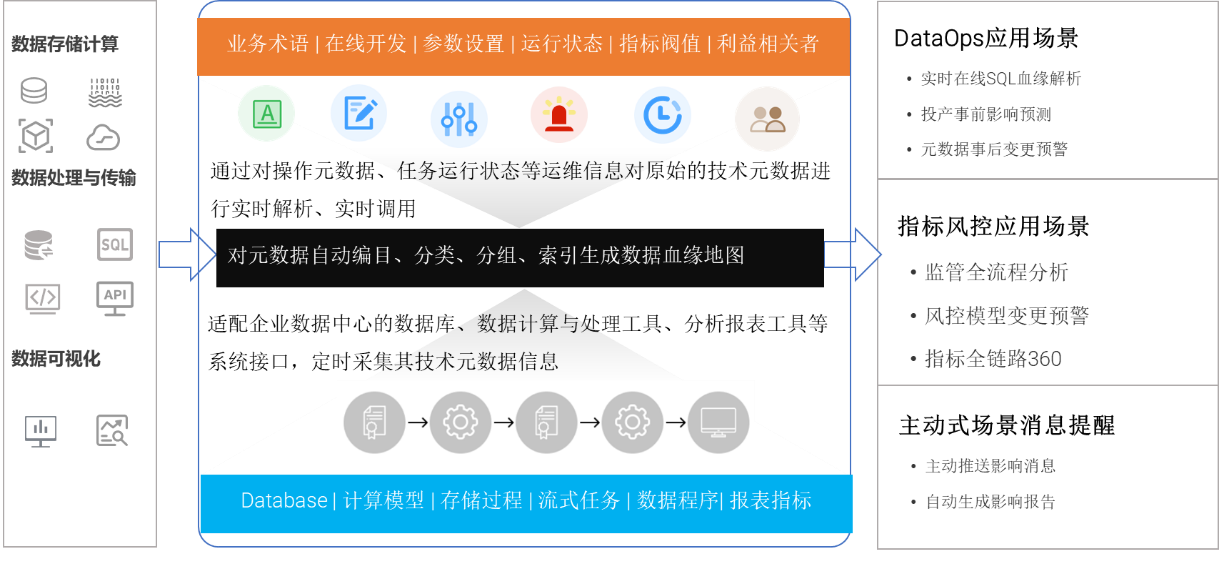
例如,在金融领域中,对于某个特定的数据字段,只有当我们明确了它所对应的业务流程,比如是贷款审批流程中的一个关键数据项,以及相关的业务规则,如额度限制等,同时了解到涉及的利益相关者,如信贷员、客户等,还有其代表的指标含义,如风险评估指标等,我们才能真正理解这个数据元素在整个业务体系中的地位和作用,就像只有知道了一颗星星在星系中的具体位置和它所代表的意义,我们才能更好地理解整个星系的运行规律。
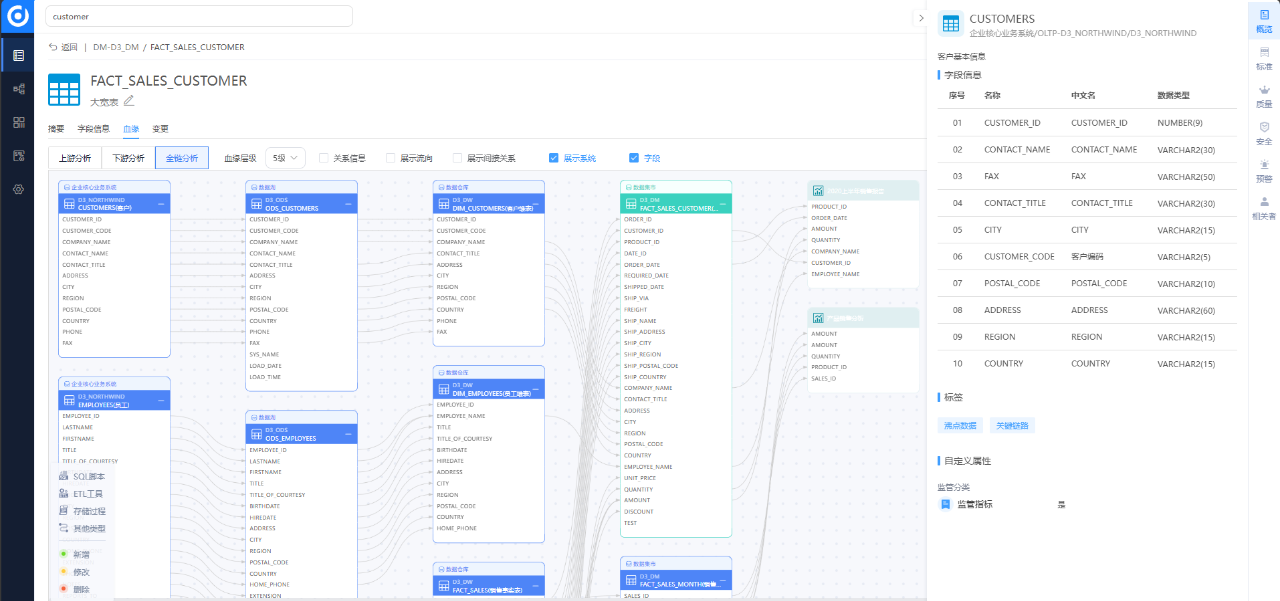
将业务融入到数据血缘,往往不少于以下管理内容:
1.明确业务与血缘的边界:
业务:指的是公司的数据活动(如数据治理、数据开发)、管理流程、业务目标、执行策略等。
血缘:是数据从源头流向目标的运行路径,记录了数据如何被转换、处理、存储和使用的轨迹。
2.建立业务与血缘的映射关系:
在血缘关系图中,为每个数据元素(如表单、字段、代码片段、数据任务)绑定元数据。
使用数据字典或数据模型文档来详细解释每个数据元素的业务含义和用途。
3.设计业务氛围信息层:
在血缘关系图上叠加业务氛围信息层,包括数据标准、业务流程、业务规则、利益相关者、指标含义等。
使用可视化工具来展示这些信息,使非技术人员也能理解数据的业务含义和场景。
4.保持业务与血缘的有机隔离:
在存储和设计上,确保业务氛围信息和血缘数据分别存储,但可以通过元数据进行关联。
使用API或中间件来连接业务系统和血缘管理系统,实现业务与业务实时同步与一致。
五、您期待哪些数据血缘应用场景
在日益复杂的数据环境中,数据血缘的应用场景变得至关重要。数据血缘,即数据在整个生命周期中的来源、转换、流向和最终使用的完整记录,为企业提供了对数据流动和影响的深入理解。以下几个数据血缘应用场景或许值得您期待。
模型变更影响预测
数据模型是应用系统不可或缺的基础。随着业务需求的变化,应用系统功能模块的升级就会要求数据模型跟随着调整。然而,这种变更如果不提前制定预案,将可能直接影响上下游应用的稳定运行。为了降低风险,我们需要在投产前进行有效的评估,生成影响报告通知相应责任人及时分析应对。
场景准备:
· 制定数据模型投产计划。
· 生成数据模型版本变更报告,明确变更内容和范围。
· 创建模型变更影响预测应用场景,设置场景责任人及相应参数、规则。
实现效果:
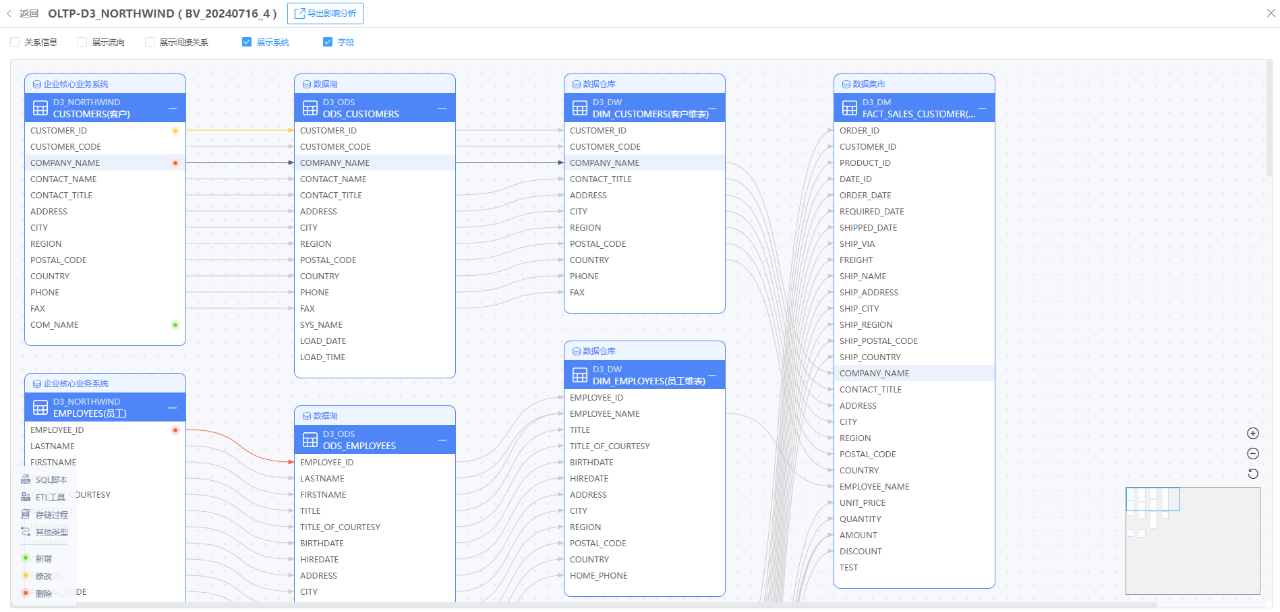
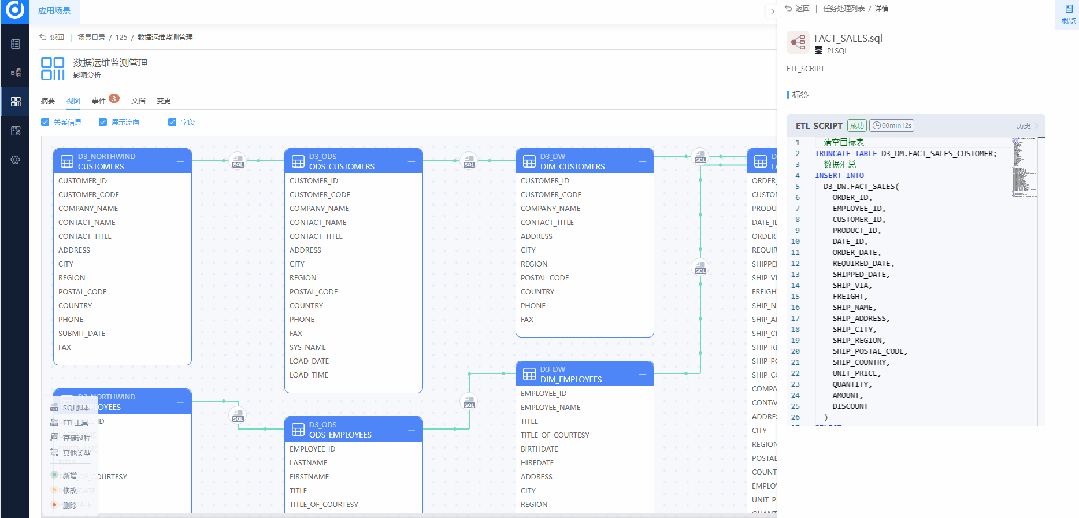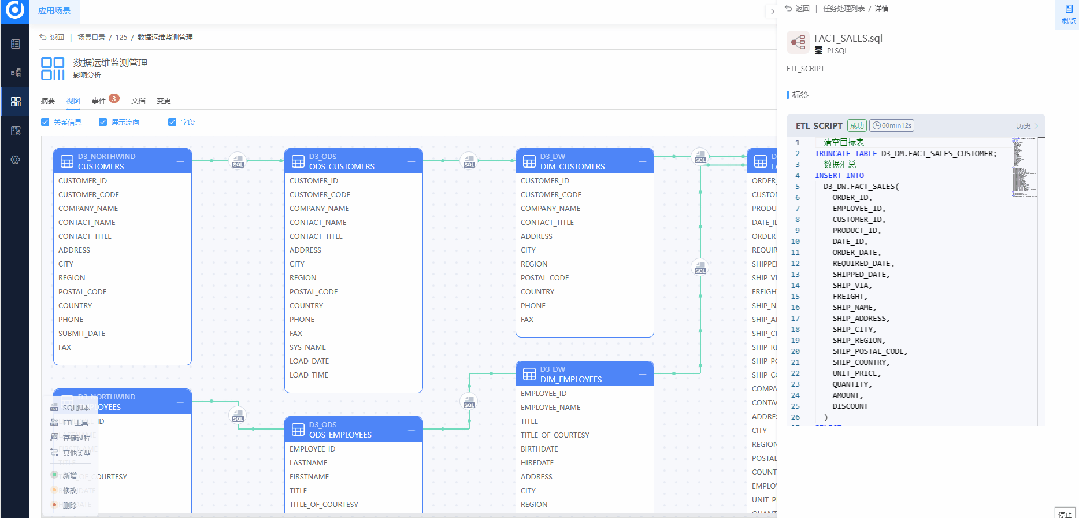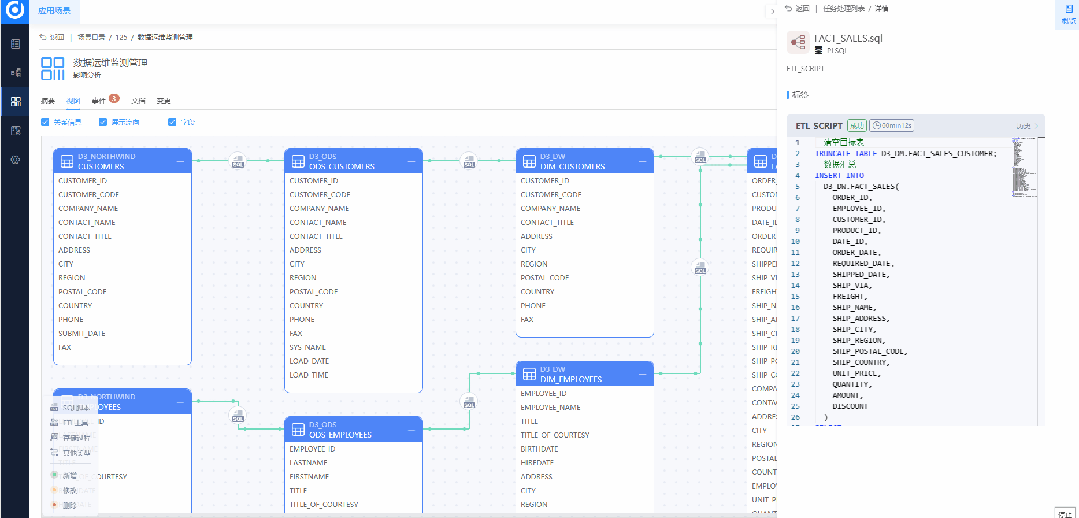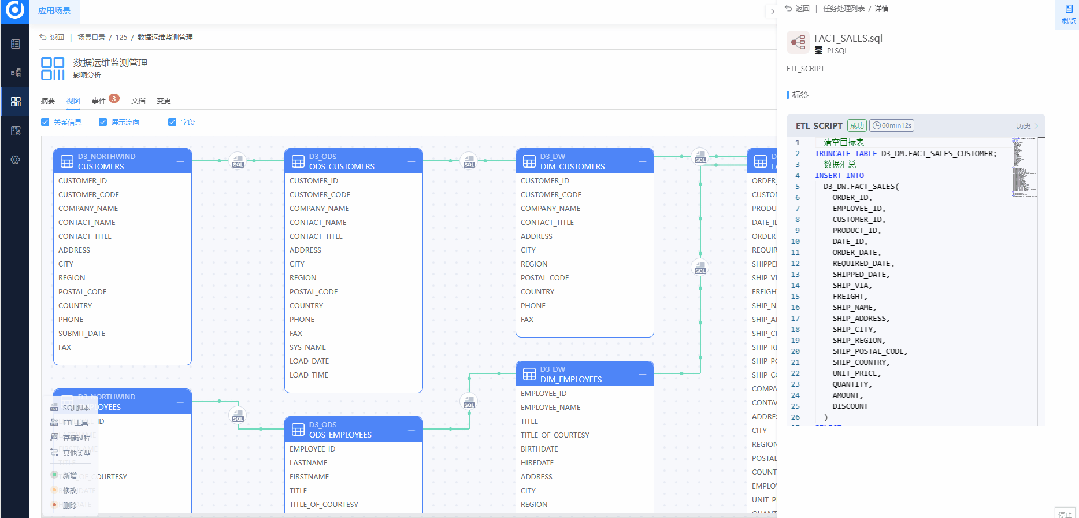
· 自动化生成系统上下游的全域数据血缘链路图,清晰展示数据流动方向。
· 在血缘链路中通过颜色自动标注新增、变更、删除的表和字段,生成详细的影响预测报告,包括潜在风险、影响范围和应对措施建议。
· 以电子邮件、即时消息等形式即时通知上下游IT责任人,确保他们了解变更内容及其潜在影响。
风险指标监测预警
企业存在着诸多如信用风险、市场风险、资金流动性风险、操作风险等数据指标。对于这些关键指标,任何微小的变化都可能对企业产生重大影响。因此,需要持续时刻关注、监测这些指标的变化和趋势,同时能够精准定位这些指标、并保障其应用系统的稳定运行,指标非正常运行的事务能及时被监控、被预警,
场景准备:
· 整合风险指标的氛围信息,如历史参考数据、行业趋势、法律规范等。
· 采集算法、参数和运行状态数据,以便进行实时监控和分析。
· 创建风险指标监控场景,设置监控规则和预警条件。
实现效果:
· 实时监控风险指标的变化和趋势,及时发现潜在风险。
· 自动化触发预警通知,确保利益相关者即刻了解风险情况。
· 提供风险分析和建议措施,帮助企业应对潜在风险并优化决策过程。
六、结论
数据血缘作为数据管理与分析的关键手段,正逐步彰显出其独有的活力与魅力。企业借助数据链路技术能够更为精确定位数据问题,实时监控数据的流动情况,精准预测元数据变化所产生的影响,进而提升数据管理的效率,更高效、更准确地理解并运用数据资源,为数字化转型给予强有力的支持。


