


数据流动的密码:揭开血缘关系的全貌
数据血缘描述了数据从源头到目的地的流动和转换过程,尽管各类业务利益相关者对数据血缘的期望和需求各不相同,但对其核心认知是一致的。本文将深入探讨数据血缘的不同类型及其依赖关系,帮助大家更好地理解这一复杂但关键的主题。
一、数据血缘类型的全貌
主题:数据血缘可以分为元数据血缘和数据值血缘。元数据血缘关注数据的处理和转换文档,而数据值血缘则侧重于数据实例层的转换和跟踪。
层次:数据血缘可以在四个层次上记录:业务层、概念层、逻辑层和物理层。不同层次使用不同的元数据来描述数据血缘。
方向:根据数据血缘的方向,可以分为横向数据血缘和纵向数据血缘。横向血缘展示数据从起点到终点的流动,而纵向血缘则连接不同层次的数据组件。
方法:数据血缘的记录方法分为描述型和自动型。描述型血缘通过手工记录元数据,而自动型血缘则通过自动化工具采集和记录元数据。
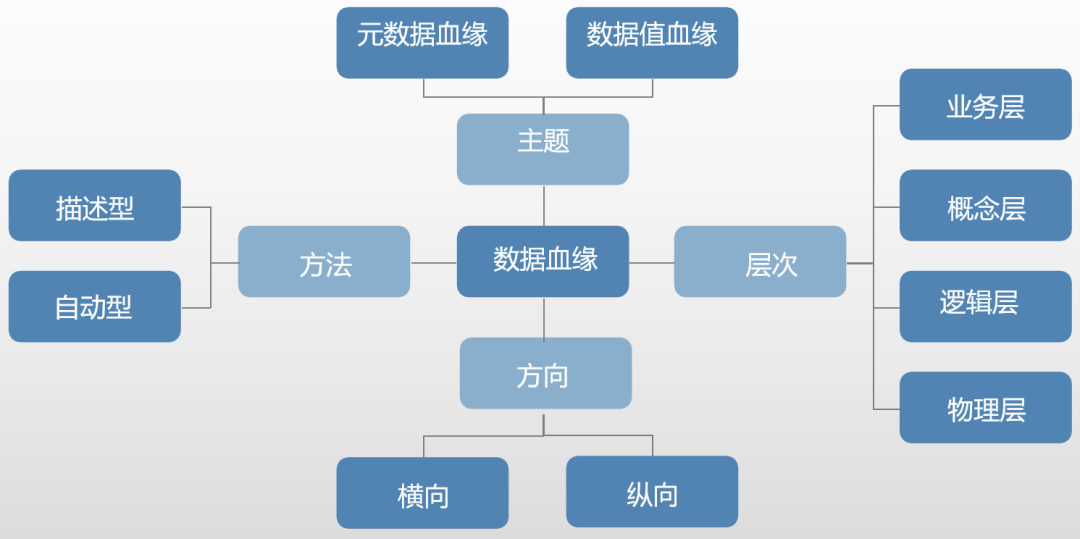
数据血缘分类概念图
1、元数据血缘和数据值血缘
数据血缘的主题可以分为元数据血缘和数据值血缘,不同的利益相关者对每种血缘类型的关注点也不一样。
- 元数据血缘
数据管理和IT专业人员通常将数据血缘理解为由元数据进行的数据处理和转换文档。元数据血缘可以在任何抽象层记录描述,不同层次使用不同的元数据。
- 数据值血缘
业务利益相关者更加关注数据实例层的转换,希望看到整个数据链中跟踪数据值的变化。
例如,如果管理报告中总收入为100万欧元,他们希望将它追溯到单个合同金额以及了解从合同金额到100万欧元间的转换规则。这种需求被称为“数据值血缘”,通常只在物理层记录。
因此,在与不同利益相关者群体进行沟通时,应该考虑到元数据血缘和数据值血缘间的差异。
2、不同记录层的数据血缘
数据血缘的记录层次包括业务层、概念层、逻辑层和物理层。详情可点击《数据血缘元模型:架起业务与技术的桥梁》这篇文章查看。此外,还想强调以下两点:
· 不同企业采用不同数量的层级和组件来描述数据血缘,且对这些层级的命名和定义也各有差异。
· 根据我的实践经验总结,建议分类是基于通用实践的,每家企业应根据自身需求选择适合的分类方式。
3、横向和纵向数据血缘
数据血缘记录的方向分为横向和纵向数据血缘,如下图。
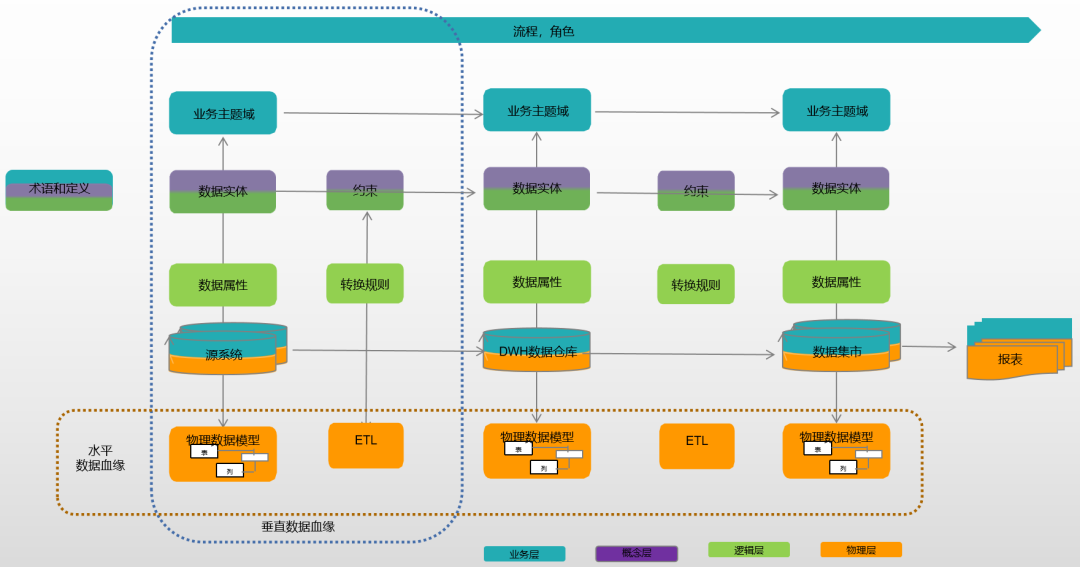
自由格式的数据血缘元模型
横向数据血缘是最常见的数据血缘类型,描述了数据链上两个位置之间数据路径的数据血缘,展示数据从创建点到应用点的流动。可以在业务层、概念层、逻辑层和物理层上记录横向数据血缘。
纵向数据血缘是链接不同层级中组件的数据血缘。例如业务主题域、数据实体、数据属性以及数据库表和列之间的关系。
4、描述型和自动型数据血缘
数据血缘的分类依据之一是记录方法,这是第四个关键因素。记录方法主要分为描述型和自动型两种。
- 描述型数据血缘:指将元数据数据血缘手工记录到数据存储库中。
- 自动型数据血缘:将通过实施自动扫描并采集元数据的过程,并将元数据数据血缘记录到存储库中。
这两种方法各有其适用的场景,同时也具备各自的优点和局限性。可从以下几个方面来选择数据血缘的记录方法:
1)数据模型层
描述型数据血缘适合在业务层、概念层和逻辑层记录元数据血缘,但在物理层手工记录数据血缘是非常困难的。以我的实践经验为例,整理包含数千行数据的Excel文件可能需要耗费数百个工时,效率极低。
相比之下,自动型数据血缘更适用于采集物理层的数据血缘信息。但需要注意的是,从逻辑层到物理层的数据血缘映射,通常仍需通过手工方式完成,以确保准确性和一致性。
2)所需资源
无论是创建还是维护阶段,数据血缘的记录都是一项时间和资源密集型的工作。我们需要持续关注数据血缘的变化,并及时调整。自动型数据血缘在初始阶段,创建读取和上传元数据的自动化流程需要大量资源;之后,随着新版本的发布,数据血缘信息应能自动更新;然而,如果涉及新应用程序,则需要手工编码来完成。描述型数据血缘,在设计和维护阶段需要持续投入资源。
二、数据血缘间的相互依赖
之所以想分享下各种数据血缘之间的依赖,是因为在实践中,我经常遇到有关沟通数据血缘的挑战。比如:元数据架构师说:“我们要开发一个横向数据血缘的未来态架构(FSA)。”我的第一反应是:”在哪个层上?横向数据血缘可以在四个层级上记录。”很明显,元数据架构师说的是物理层元数据血缘,只是将其简称为横向数据血缘。
我们先来分析这些数据血缘间可能的组合和依赖,如下:
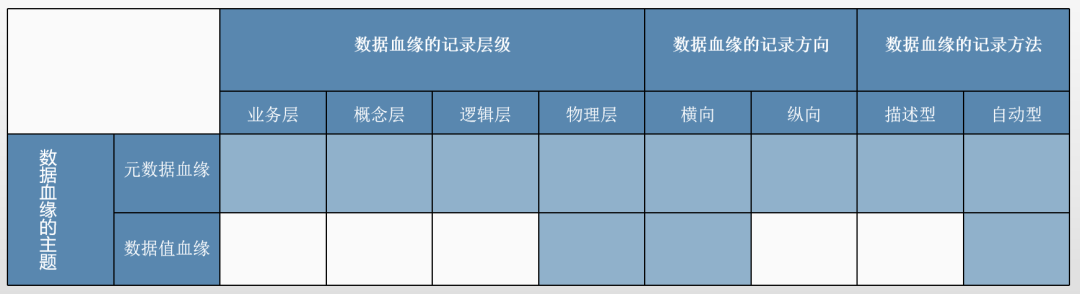
数据血缘的主题与其他数据血缘分类之间的依赖关系
· 数据血缘的主题和数据血缘的记录层级
元数据血缘可在被记录在每个抽象层级上,记录的元数据组件和元素会有所差异。无论何种情况,元数据血缘都用于描述数据流和数据转换的过程。而数据值血缘仅能在物理层记录,本文仅针对物理层中存在的数据实例进行讨论。
· 数据血缘的主题和数据血缘的记录方向
元数据血缘可从两个方向进行记录:横向数据血缘展示数据沿数据链的流动路径,而纵向数据血缘则连接不同抽象层级的元数据组件。数据值血缘仅能记录在横向数据血缘中,因为数据实例仅存在于物理层。
· 数据血缘的主题和数据血缘的记录方法
元数据血缘的记录可采用描述型和自动型方法,而数据值血缘由于仅存在于物理层,因此更适合通过自动型方法进行记录。
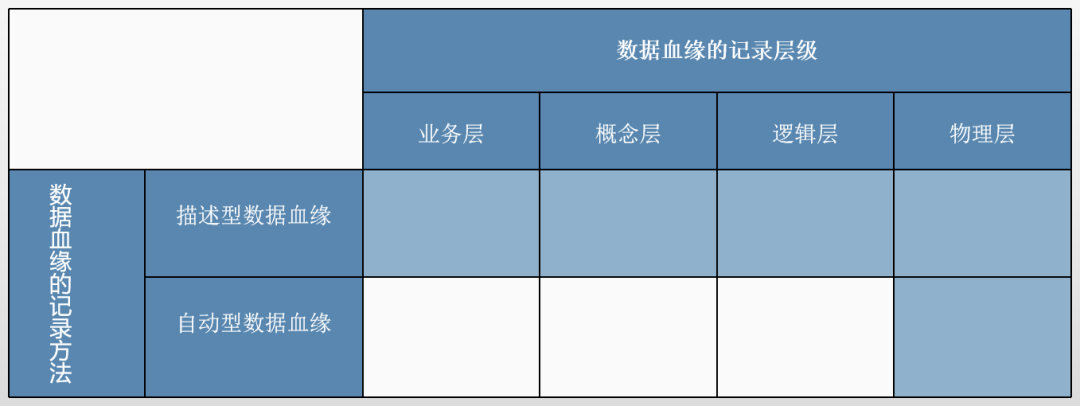
数据血缘的记录方法和记录层级之间的依赖关系
· 数据血缘的记录方法和数据血缘的记录层级
记录数据血缘的描述性方法适用于所有层级。在实践中,我曾见过使用Excel或Word文件记录物理层数据血缘的情况,但这是一种最不推荐的方式。描述性方法更适合用于记录业务层和概念层的数据血缘,因为这些层级缺乏自动记录的方法。对于物理层,强烈建议仅采用自动型数据血缘记录方法。逻辑层则是一个分区:逻辑模型既可以通过逆向工程从物理模型中生成,也可以在数据建模工具中手动创建。
综上所述,数据血缘作为数据管理中的核心概念,其复杂性和多样性要求我们在实际应用中采取灵活且系统化的方法。通过深入理解数据血缘的四大因素——主题、层次、方向和方法,希望大家能够更好地满足不同利益相关者的需求,并有效应对数据管理中的挑战。无论是元数据血缘还是数据值血缘,无论是横向还是纵向数据血缘,亦或是描述型与自动型记录方法,每种类型都有其独特的应用场景和优势。
在实际操作中,企业应根据自身的业务需求和技术架构,选择合适的数据血缘记录方式,并确保其与整体数据治理策略保持一致。同时,随着数据环境的不断变化,数据血缘的记录和维护也需要持续投入资源和精力,以确保其准确性和时效性。


